
Introduction
PolyBase is a technology that accesses data outside of the database via the t-sql language. In SQL Server 2016, it allows you to run queries on external data in Hadoop or to import/export data from Azure Blob Storage. Queries are optimized to push computation to Hadoop. PolyBase does not require you to install additional software to your Hadoop environment. Querying external data uses the same syntax as querying a database table. This all happens transparently. PolyBase handles all the details behind-the-scenes, and no knowledge about Hadoop is required by the end user to query external tables.
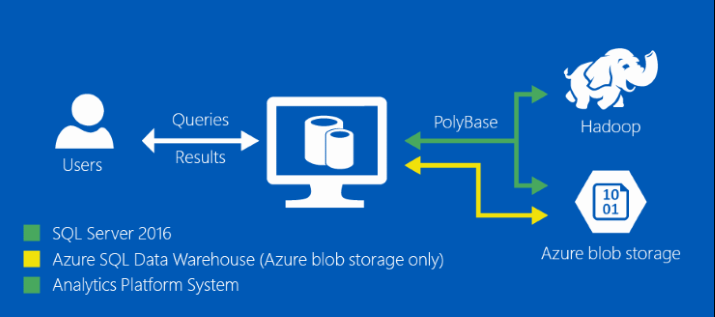
PolyBase Architecture
Control/Head Node: Similar to Hadoop's NameNode/Job Tracker, PolyBase will have one Control Node. The Control Node is a SQL Server instance that you configure that runs the PolyBase Engine Service. Think of the Control Node as the point of contact for the client applications across the cluster. Its tasks will include:
- Parsing of the executed T-SQL queries
- Optimizing and building query plans
- Controlling execution of parallel queries
- Returning results to client applications
Known Limitations
PolyBase has the following limitations:
- The maximum possible row size, including the full length of variable length columns, can not exceed 32 KB in SQL Server or 1 MB in Azure SQL Data Warehouse.
- PolyBase doesn’t support the Hive 0.12+ data types (i.e. Char(), VarChar())
- When exporting data into an ORC File Format from SQL Server or Azure SQL Data Warehouse text heavy columns can be limited to as few as 50 columns due to java out of memory errors. To work around this, export only a subset of the columns.
- Cannot Read or Write data encrypted at rest in Hadoop. This includes HDFS Encrypted Zones or Transparent Encryption.
- PolyBase cannot connect to a Hortonworks instance if KNOX is enabled.
- If you are using Hive tables with transactional = true, PolyBase cannot access the data in the Hive table's directory.
Polybase Scenarios
- Hadoop for Staging
- Ambient data from Hadoop
- Export Dimensions to Hadoop
- Hadoop as a Data Archive
Install PolyBase
Since PolyBase is now part of SQL Server, we can use the SQL Server 2016 installation media to do the installation. And because it was designed to interact with Hadoop, we will need to install the Oracle Java SE Runtime Environment (JRE) 7.51 (x64) or higher prior to running the SQL Server 2016 installation media.
You can take help from the below link to install PolyBase feature in SQL Server 2016. You can install it as a single node installation or a PolyBase scale out group. You can install PolyBase on only one SQL Server instance per machine. The installation process adds three user databases (DWConfiguration, DWDiagnostics and DWQueue) and two services (SQL Server PolyBase Engine and SQL Server PolyBase Data Movement Service).
https://docs.microsoft.com/en-us/sql/relational-databases/polybase/polybase-installationConfirm Installation
After installation, run the following command to confirm that PolyBase has been successfully installed. If PolyBase is installed, returns 1; otherwise, 0.
SELECT SERVERPROPERTY ('IsPolybaseInstalled') AS IsPolybaseInstalled;
Configure PolyBase
After installing, you must configure SQL Server to use either your Hadoop version or Azure Blob Storage. PolyBase supports two Hadoop providers, Hortonworks Data Platform (HDP) and Cloudera Distributed Hadoop (CDH).
PolyBase Connectivity Configuration
*********************************************
These are the Hadoop connectivity settings and their corresponding supported Hadoop data sources. Only one setting can be in effect at a time. Options 1, 4, and 7 allow multiple types of external data sources to be created and used across all sessions on the server.
Option 0: Disable Hadoop connectivity
Option 1: Hortonworks HDP 1.3 on Windows Server
Option 1: Azure blob storage (WASB[S])
Option 2: Hortonworks HDP 1.3 on Linux
Option 3: Cloudera CDH 4.3 on Linux
Option 4: Hortonworks HDP 2.0 on Windows Server
Option 4: Azure blob storage (WASB[S])
Option 5: Hortonworks HDP 2.0 on Linux
Option 6: Cloudera 5.1, 5.2, 5.3, 5.4, 5.5, 5.9, 5.10, 5.11, and 5.12 on Linux
Option 7: Hortonworks 2.1, 2.2, 2.3, 2.4, 2.5, and 2.6 on Linux
Option 7: Hortonworks 2.1, 2.2, and 2.3 on Windows Server
Option 7: Azure blob storage (WASB[S])
RECONFIGURE
Updates the run value (run_value) to match the configuration value (config_value). The new configuration value that is set by sp_configure does not become effective until the run value is set by the RECONFIGURE statement.
After running RECONFIGURE, you must stop and restart the SQL Server service. Note that when stopping the SQL Server service, the two additional PolyBase Engine and Data Movement Service will automatically stop. After restarting the SQL Server engine service, re-start these two services again (they won’t start automatically).
a) List all available configuration settings
EXEC sp_configure;
The result returns the option name followed by the minimum and maximum values for the option. The config_value is the value that SQL, or PolyBase, will use when reconfiguration is complete. The run_value is the value that is currently being used. The config_value and run_value are usually the same unless the value is in the process of being changed.
b) List the configuration settings for one configuration name
EXEC sp_configure @configname='hadoop connectivity';
c) Set Hadoop connectivity
This example sets PolyBase to option 7. This option allows PolyBase to create and use external tables on Hortonworks 2.1, 2.2, and 2.3 on Linux
--Configure external tables to reference data on Hortonworks 2.1, 2.2, and 2.3 on Linux, and Azure blob storage
sp_configure @configname = 'hadoop connectivity', @configvalue = 7;
GO
RECONFIGURE
GO
You must restart SQL Server using services.msc. Restarting SQL Server restarts these services:
SQL Server
SQL Server PolyBase Data Movement Service
SQL Server PolyBase Engine
Pushdown configuration
******************************
To improve query performance, enable pushdown computation to a Hadoop cluster:
a) Find the file yarn-site.xml in the installation path of SQL Server. Typically, the path is:
C:\Program Files\Microsoft SQL Server\MSSQL13.SQL2016\MSSQL\Binn\Polybase\Hadoop\conf
b) On the Hadoop machine, find the analogous file in the Hadoop configuration directory. In the file, find and copy the value of the configuration key yarn.application.classpath.
Example:
/etc/hadoop/conf,/usr/hdp/current/hadoop-client/*,/usr/hdp/current/hadoop-client/lib/*,/usr/hdp/current/hadoop-hdfs-client/*,/usr/hdp/current/hadoop-hdfs-client/lib/*,/usr/hdp/current/hadoop-yarn-client/*,/usr/hdp/current/hadoop-yarn-client/lib/*
c) On the SQL Server machine, in the yarn.site.xml file, find the yarn.application.classpath property. Paste the value from the Hadoop machine into the value element.
d) For all CDH 5.X versions, you will need to add the mapreduce.application.classpath configuration parameters either to the end of your yarn.site.xml file or into the mapred-site.xml file. HortonWorks includes these configurations within the yarn.application.classpath configurations.
Note: You could copy yarn-site.xml, mapred-site.xml, hdfs-site.xml, core-site.xml, hive-site.xml files from your hadoop cluster to the conf folder of PolyBase (C:\Program Files\Microsoft SQL Server\MSSQL13.SQL2016\MSSQL\Binn\Polybase\Hadoop\conf) to have the same parameters on both environments and for easy setup.
SELECT * FROM sys.dm_exec_compute_nodes;

Create T-SQL objects
After the necessary configuration, now you can create T-SQL objects.
b) Create External File Format
External table file format is specified according to the format of the data you have in your external source ie; Hadoop
-- data formatted in text-delimited files
-- data formatted as RCFiles
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
-- data formatted as ORC files
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT_TYPE = ORC,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;

If you don't set the above properties, you may encounter below error in SSMS.
and if you check from the application tracking URL you will see error like below.

Export data
-- Enable INSERT into external table
sp_configure 'allow polybase export', 1;
reconfigure
--Create external Table with your desired format
CREATE EXTERNAL TABLE bigdata.dbo.testExport (
deptno int,
dname varchar(10),
loc varchar(10)
)
WITH (
LOCATION='/tmp/testExportData',
DATA_SOURCE = ds_hdp2_6,
FILE_FORMAT = myfileformat ,
REJECT_TYPE = VALUE,
REJECT_VALUE = 0
);
-- Export data: Move old data to Hadoop while keeping it query-able via an external table.
INSERT INTO bigdata.dbo.testExport
SELECT * FROM dept
--Verify the location where files for the external table generated.

Manage PolyBase
Use the catalog views to manage PolyBase operations.
select * from sys.external_tables
select * from sys.external_data_sources
select * from sys.external_file_formats
PolyBase Logs
Logs related to PolyBase are located at
C:\Program Files\Microsoft SQL Server\MSSQL13.InstanceName\MSSQL\Log\Polybase.

****************************
After the necessary configuration, now you can create T-SQL objects.
a) Create External Data Source
DROP EXTERNAL DATA SOURCE mydatasource;
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://nn01:8020'
);
LOCATION is the name node address with port.
External table file format is specified according to the format of the data you have in your external source ie; Hadoop
-- data formatted in text-delimited files
DROP EXTERNAL FILE FORMAT myfileformat;
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR =',')
);
-- data formatted as RCFiles
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
-- data formatted as ORC files
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT_TYPE = ORC,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;
c) Create External Table
DROP EXTERNAL TABLE ext_dept_on_hdfs;
CREATE EXTERNAL TABLE ext_dept_on_hdfs (
deptno int,
dname varchar(10),
loc varchar(10)
)
WITH (
LOCATION='/apps/hive/warehouse/scott.db/dept/dept.csv',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
LOCATION is the HDFS location where files to be read by external table are residing.
d) Query External Table
SELECT * from ext_dept_on_hdfs

PUSHDOWN Computation To Hadoop Cluster
You can push-down computation to Hadoop for PolyBase queries. Use predicate pushdown to improve performance for a query that selects a subset of rows from an external table.
For example: SELECT * FROM SensorData WHERE Speed > 65;
In above example, SQL Server 2016 initiates a map-reduce job to retrieve the rows that match the predicate on Hadoop. Because the query can complete successfully without scanning all of the rows in the table, only the rows that meet the predicate criteria are copied to SQL Server. This saves significant time and requires less temporary storage space
SQL Server allows the following basic expressions and operators for predicate pushdown.
You can enable pushdown forcefully if required and disable as well.
select count(*) from ext_dept_on_hdfs OPTION (FORCE EXTERNALPUSHDOWN);
select count(*) from ext_dept_on_hdfs OPTION (DISABLE EXTERNALPUSHDOWN);
Note: For push down you have to have the below two properties set in your mapred-site.xml in PolyBase conf folder. - Binary comparison operators ( <, >, =, !=, <>, >=, <= ) for numeric, date, and time values.
- Arithmetic operators ( +, -, *, /, % ).
- Logical operators (AND, OR).
- Unary operators (NOT, IS NULL, IS NOT NULL).
The operators BETWEEN, NOT, IN, and LIKE might be pushed-down. The actual behavior depends on how the query optimizer rewrites the operator expressions as a series of statements that use basic relational operators.
You can enable pushdown forcefully if required and disable as well.
select count(*) from ext_dept_on_hdfs OPTION (FORCE EXTERNALPUSHDOWN);
select count(*) from ext_dept_on_hdfs OPTION (DISABLE EXTERNALPUSHDOWN);
<property>
<name>mapred.min.split.size</name>
<value>1073741824</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
If you don't set the above properties, you may encounter below error in SSMS.
Cannot execute the query "Remote
Query" against OLE DB provider "SQLNCLI11" for linked server
"(null)". Hadoop Job Execution failed. Tracking URL is http://nn01:8088/cluster/app/application_1514186075960_0049
and if you check from the application tracking URL you will see error like below.

Export data
-- Enable INSERT into external table
sp_configure 'allow polybase export', 1;
reconfigure
--Create external Table with your desired format
CREATE EXTERNAL TABLE bigdata.dbo.testExport (
deptno int,
dname varchar(10),
loc varchar(10)
)
WITH (
LOCATION='/tmp/testExportData',
DATA_SOURCE = ds_hdp2_6,
FILE_FORMAT = myfileformat ,
REJECT_TYPE = VALUE,
REJECT_VALUE = 0
);
-- Export data: Move old data to Hadoop while keeping it query-able via an external table.
INSERT INTO bigdata.dbo.testExport
SELECT * FROM dept
--Verify the location where files for the external table generated.

Use the catalog views to manage PolyBase operations.
select * from sys.external_tables
select * from sys.external_data_sources
select * from sys.external_file_formats
Dynamic Management Views
-- Returns errors that occur on PolyBase compute nodes.
select * from sys.dm_exec_compute_node_errors
-- additional information about the performance and status of all PolyBase nodes.
select * from sys.dm_exec_compute_node_status
-- information about nodes used with PolyBase data management
select * from sys.dm_exec_compute_nodes
-- information about all steps that compose a given PolyBase request or query, lists one row per query step
select * from sys.dm_exec_distributed_request_steps
-- information about all requests currently or recently active in PolyBase queries, lists one row per request/query
select * from sys.dm_exec_distributed_requests
-- information about all SQL query distributions as part of a SQL step in the query, data for the last 1000 requests
select * from sys.dm_exec_distributed_sql_requests
-- information about all of the DMS services running on the PolyBase compute nodes
select * from sys.dm_exec_dms_services
-- information about all workers completing DMS steps
select * from sys.dm_exec_dms_workers
-- information about external PolyBase operations
select * from sys.dm_exec_external_operations
-- information about the workload per worker
select * from sys.dm_exec_external_work
Monitor PolyBase
-- Find the longest running query
SELECT execution_id, st.text, dr.total_elapsed_time
FROM sys.dm_exec_distributed_requests dr
cross apply sys.dm_exec_sql_text(sql_handle) st
ORDER BY total_elapsed_time DESC;
-- Find the longest running step of the distributed query plan
SELECT execution_id, step_index, operation_type, distribution_type,
location_type, status, total_elapsed_time, command
FROM sys.dm_exec_distributed_request_steps
WHERE execution_id = 'QID4547'
ORDER BY total_elapsed_time DESC;
-- Find the execution progress of SQL step
SELECT execution_id, step_index, distribution_id, status,
total_elapsed_time, row_count, command
FROM sys.dm_exec_distributed_sql_requests
WHERE execution_id = 'QID4547' and step_index = 1;
-- Find the execution progress of DMS step
SELECT execution_id, step_index, dms_step_index, status,
type, bytes_processed, total_elapsed_time
FROM sys.dm_exec_dms_workers
WHERE execution_id = 'QID4547'
ORDER BY total_elapsed_time DESC;
-- Find the information about external DMS operation
SELECT execution_id, step_index, dms_step_index, compute_node_id,
type, input_name, length, total_elapsed_time, status
FROM sys.dm_exec_external_work
WHERE execution_id = 'QID4547' and step_index = 7
ORDER BY total_elapsed_time DESC;
PolyBase Logs
Logs related to PolyBase are located at
C:\Program Files\Microsoft SQL Server\MSSQL13.InstanceName\MSSQL\Log\Polybase.
eg; C:\Program Files\Microsoft SQL Server\MSSQL13.SQL2016\MSSQL\Log\Polybase

1 comment:
Very nice post.Keep maintaining your blog with Unique content.
big data online training
Post a Comment